在移植
Kernel-6.6.0至RK3588时遇到Unable to handle kernel paging request at virtual address xxxxxxx
问题
具体情况如下:
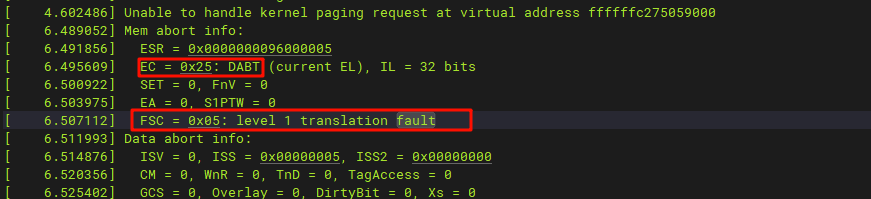
[ 4.602486] Unable to handle kernel paging request at virtual address ffffffc275059000
[ 6.489052] Mem abort info:
[ 6.491856] ESR = 0x0000000096000005
[ 6.495609] EC = 0x25: DABT (current EL), IL = 32 bits
[ 6.500922] SET = 0, FnV = 0
[ 6.503975] EA = 0, S1PTW = 0
[ 6.507112] FSC = 0x05: level 1 translation fault
[ 6.511993] Data abort info:
[ 6.514876] ISV = 0, ISS = 0x00000005, ISS2 = 0x00000000
[ 6.520356] CM = 0, WnR = 0, TnD = 0, TagAccess = 0
[ 6.525402] GCS = 0, Overlay = 0, DirtyBit = 0, Xs = 0
[ 6.530712] swapper pgtable: 4k pages, 39-bit VAs, pgdp=0000000001f2b000
[ 6.537404] [ffffffc275059000] pgd=0000000000000000, p4d=0000000000000000, pud=0000000000000000
[ 6.546103] Internal error: Oops: 0000000096000005 [#1] SMP
[ 6.551677] Modules linked in:
[ 6.554735] CPU: 3 PID: 1016 Comm: Xorg Not tainted 6.6.0-g66f5bff17667-dirty #85
[ 6.562219] Hardware name: TOPEET RK3588 LP4 LP5 Board (DT)
[ 6.567784] pstate: 804000c9 (Nzcv daIF +PAN -UAO -TCO -DIT -SSBS BTYPE=--)
[ 6.574739] pc : percpu_counter_add_batch+0x28/0x128
[ 6.579712] lr : kbasep_os_process_page_usage_update+0x64/0xd0
[ 6.585547] sp : ffffffc084ffba80
[ 6.588864] x29: ffffffc084ffba80 x28: ffffff8105f29080 x27: 0000000000000000
[ 6.596005] x26: 0000007fe9707c98 x25: 0000000000000000 x24: 0000000000000001
[ 6.603137] x23: ffffff810b60f000 x22: ffffffc084fea020 x21: 0000000000000000
[ 6.610279] x20: 0000000000000001 x19: ffffff810daada00 x18: 0000000000000030
[ 6.617421] x17: 3a5d305b746e756f x16: 633e2d746174735f x15: 7373723e2d6d6d3e
[ 6.624562] x14: 2d746e6572727563 x13: 0000000000000000 x12: 3030303030303030
[ 6.631701] x11: 0000000000002f84 x10: 000000000000a708 x9 : ffffffc080aa3650
[ 6.638841] x8 : ffffff81018ccd30 x7 : fffffffe042d83c0 x6 : 0000000000000000
[ 6.645973] x5 : 0000000000008000 x4 : ffffffc275059000 x3 : 0000000000000000
[ 6.653105] x2 : 0000000000000020 x1 : 0000000000000001 x0 : ffffff810daadd18
[ 6.660244] Call trace:
[ 6.662687] percpu_counter_add_batch+0x28/0x128
[ 6.667308] kbasep_os_process_page_usage_update+0x64/0xd0
[ 6.672791] kbase_mmu_alloc_pgd+0xd8/0x2c0
[ 6.676978] kbase_mmu_init+0x84/0x148
[ 6.680732] kbase_context_mmu_init+0x38/0x90
[ 6.685086] kbase_create_context+0xb4/0x1e0
[ 6.689356] kbase_file_create_kctx+0x70/0x238
[ 6.693798] kbase_ioctl+0x250/0x4270
[ 6.697468] __arm64_sys_ioctl+0x3f4/0xc58
[ 6.701571] invoke_syscall.constprop.0+0x58/0x100
[ 6.706361] do_el0_svc+0xb0/0xd8
[ 6.709682] el0_svc+0x3c/0x160
[ 6.712824] el0t_64_sync_handler+0xc0/0xc8
[ 6.717010] el0t_64_sync+0x1a4/0x1a8
[ 6.720683] Code: d53b4235 d50343df d53cd044 f9401003 (b8636893)分析
这里的ffffffc275059000我们并没有办法确定是什么地址,因为它大概率是某个变量,在访问该变量时,发现它缺页,不仅缺页,改地址根本就没有分配页([ffffffc275059000] pgd=0000000000000000, p4d=0000000000000000, pud=0000000000000000)。那么我们来看看栈。 从栈的调用情况来看,它是一个ioctl的系统调用,那么该程序应该是在用户层进程了ioctl,那么可以判断是一个用户的进程因为调用syscall,在内核发生了错误。 kbase_xxx函数是maliG610的代码,最终进入到percpu_counter_add_batch发生了错误。我们先看这里:
Internal error: Oops: 0000000096000005 [#1] SMP这个表示的时寄存器ESR_EL1的值,查看ARM aarch64手册: 

EC字段为数据异常,也就是在访问MMU时数据异常,更加印证了是访问了不存在的页,同时也可以看这个: 
 上面的
上面的FSR表示一级页表翻译错误。
找到问题点
那么,该问题我们首先需要找到触发的位置,通过add2line或者decode_stacktrace.sh,当然前提是需要我们开启内核调试信息表。 因为最终我们需要使用KGDB来找到问题点,这里直接是使用KGDB: 
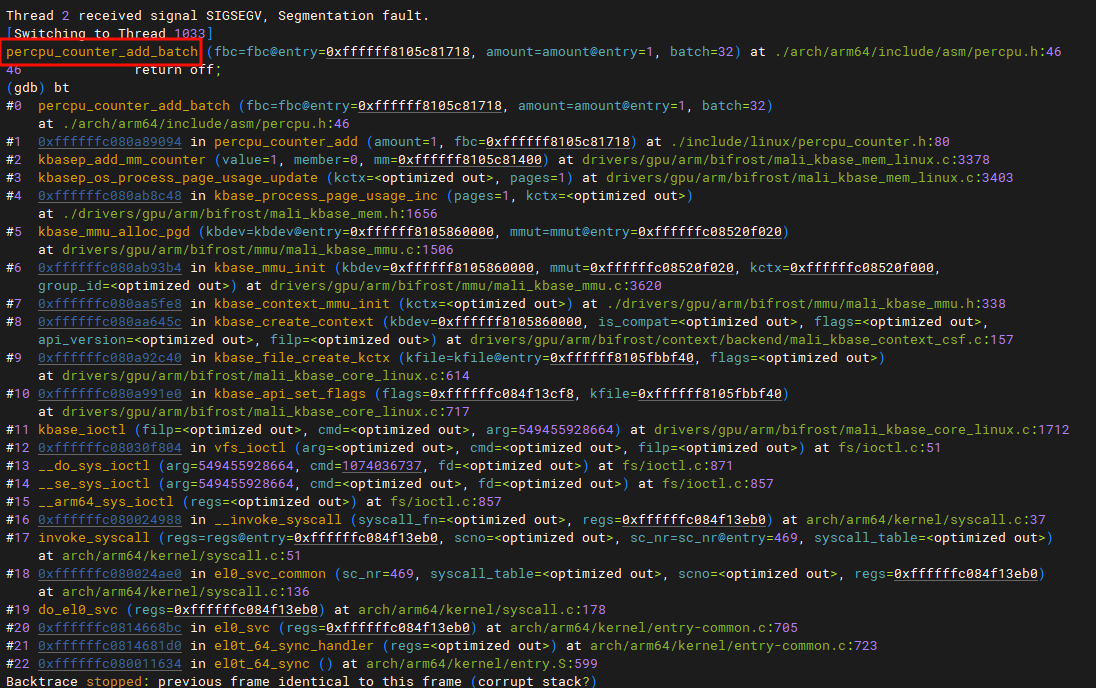 我们
我们dump出所有的内存: 
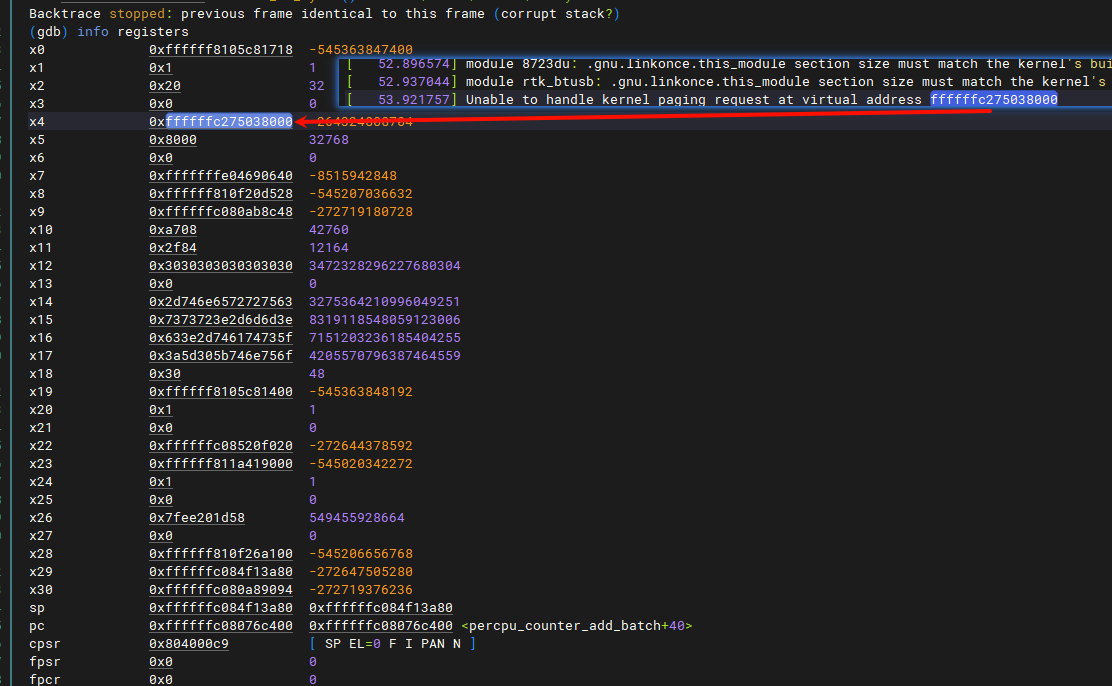 这个地址变了,因为重新启动了,这个可以忽略,只要是相同地址就行。我们从上面发现是该内存放在了
这个地址变了,因为重新启动了,这个可以忽略,只要是相同地址就行。我们从上面发现是该内存放在了x4,该寄存器为通用寄存器,一般用来做临时存放的,我们可以使用通过frame x来切换不同的帧,找到操作x4的代码段。 
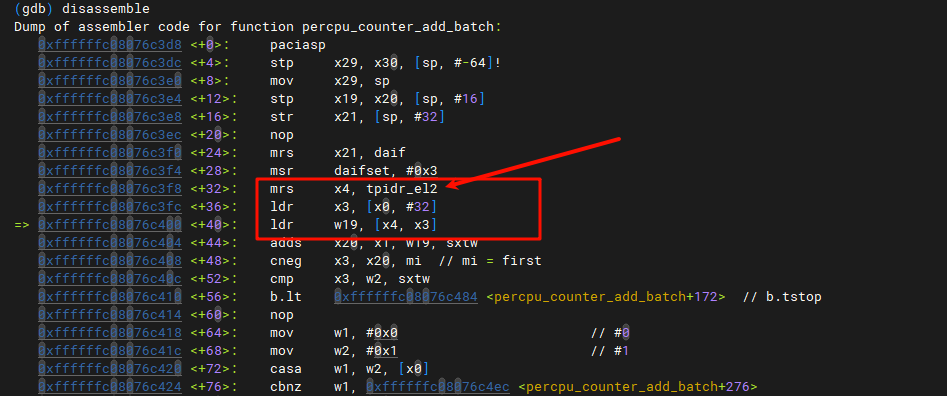 在第一个
在第一个frame中就找到了,那么对应的是:
percpu_counter_add_batch (fbc=fbc@entry=0xffffff8105c81718, amount=amount@entry=1, batch=32)
at ./arch/arm64/include/asm/percpu.h:46我们需要定位C代码与汇编的位置,我们使用objdump(交叉工具):
# 因为percpu_counter_add_batch源码在lib/percpu_counter.c
../prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-objdump -S lib/percpu_counter.o
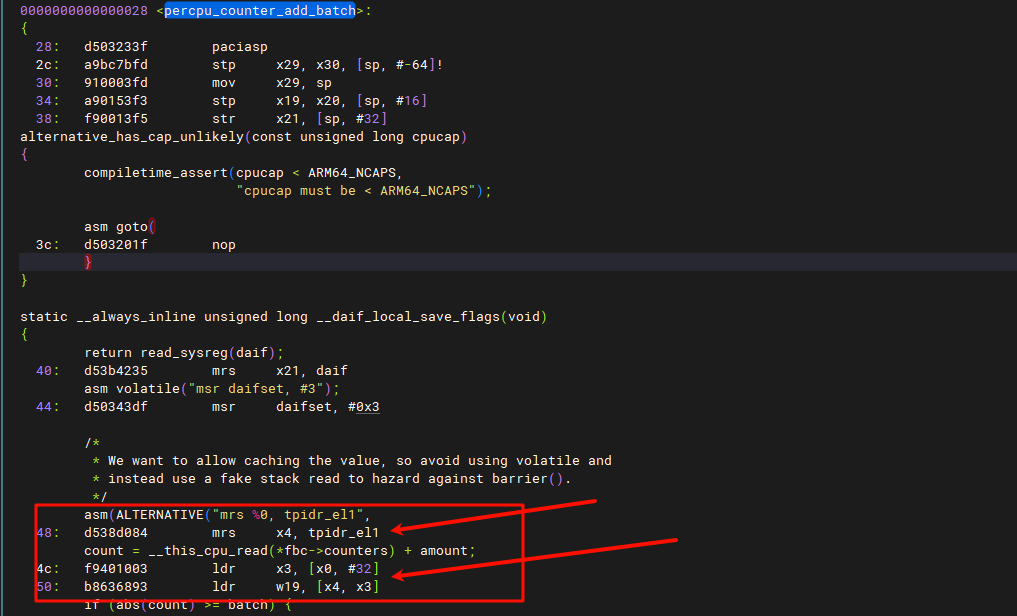 我们找到代码:
我们找到代码: 
 指令
指令mrs x4, tpidr_el1,它实际上来自函数arch/arm64/include/asm/percpu.h(通过grep查找):
static inline unsigned long __kern_my_cpu_offset(void)
{
unsigned long off;
/*
* We want to allow caching the value, so avoid using volatile and
* instead use a fake stack read to hazard against barrier().
*/
asm(ALTERNATIVE("mrs %0, tpidr_el1",
"mrs %0, tpidr_el2",
ARM64_HAS_VIRT_HOST_EXTN)
: "=r" (off) :
"Q" (*(const unsigned long *)current_stack_pointer));
return off;
}它被内联到percpu_counter_add_batch中,这里实际上跳转是比较复杂的,这里不作展开,我们在读取percpu值时会利用到寄存器tpidr_el1,所以我们需要检查传入的*fbc->counters: 


 这里时一个指针,但是指针为
这里时一个指针,但是指针为0,问题在这里,但是这只是表象,我们需要找到为什么它为0。
找到引发问题的本质
上面我们找到问题点,那么现在我们需要找到引发问题的根本在哪
这里需要向上推栈,这里我就不展开,具体调用情是(下面是反方向调用):
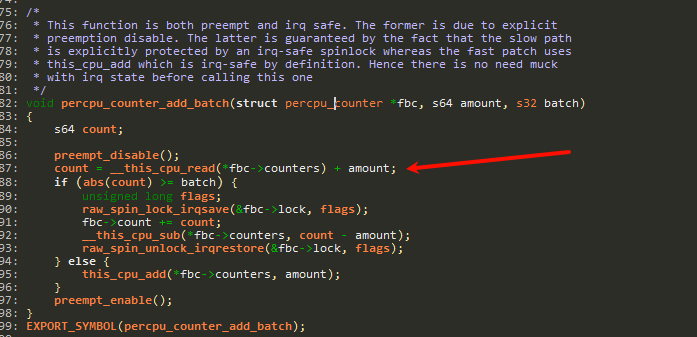
void percpu_counter_add_batch(struct percpu_counter *fbc, s64 amount, s32 batch)
static inline void percpu_counter_add(struct percpu_counter *fbc, s64 amount)
static void kbasep_add_mm_counter(struct mm_struct *mm, int member, long value)这里的kbasep_add_mm_counter:
static void kbasep_add_mm_counter(struct mm_struct *mm, int member, long value)
{
#if (KERNEL_VERSION(6, 3, 0) <= LINUX_VERSION_CODE)
percpu_counter_add(&mm->rss_stat[member], value);
#elif (KERNEL_VERSION(4, 19, 0) <= LINUX_VERSION_CODE)
/* To avoid the build breakage due to an unexported kernel symbol
* 'mm_trace_rss_stat' from later kernels, i.e. from V4.19.0 onwards,
* we inline here the equivalent of 'add_mm_counter()' from linux
* kernel V5.4.0~8.
*/
atomic_long_add(value, &mm->rss_stat.count[member]);
#else
add_mm_counter(mm, member, value);
#endif
}我们可以看到&mm->rss_stat[member]被传入到percpu_counter_add的fbc中。 那么我们来看看谁会设置mm或者rss_stat。kbasep_add_mm_counter的被调用栈如下(反向):
kbasep_add_mm_counter
kbasep_os_process_page_usage_update
kbase_process_page_usage_inc
kbase_mmu_alloc_pgd
kbase_mmu_init
kbase_context_mmu_init
kbase_create_context
kbase_file_create_kctx这里寻找的过程就不做赘述,主要的目标就是,不断寻找mm或者rss_stat的实例化或者赋值的关键代码。 我们寻找到:
struct kbase_context {
......
struct mm_struct *process_mm;
......
}
struct mm_struct {
......
struct mm_rss_stat rss_stat;
......
}struct kbase_context *kctx变量在kbase_file_create_kctx中还是NULL,但是他会在kbase_create_context初始化,我们重点看这部分代码: 
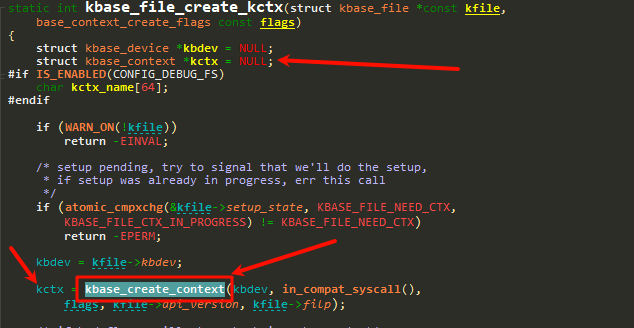

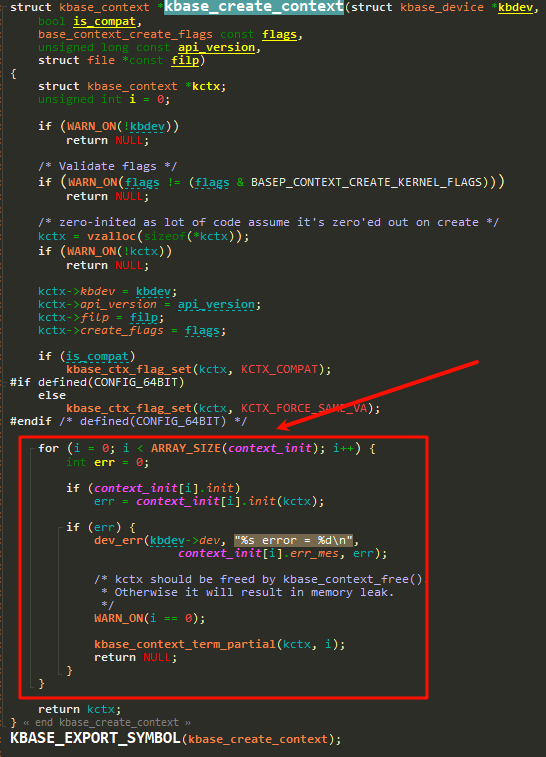 上面红框中的循环调用的是:
上面红框中的循环调用的是: 
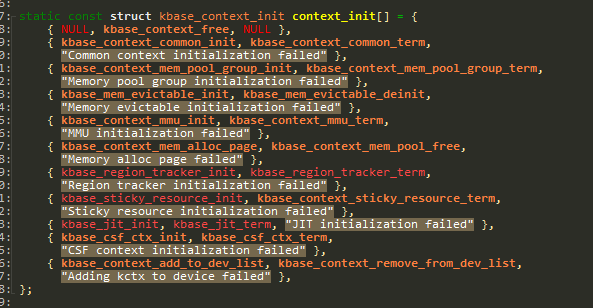 在循环代用中,我们使用正常可用的代码(另外一套)加入断点(或者使用KGDB单步),监测哪个
在循环代用中,我们使用正常可用的代码(另外一套)加入断点(或者使用KGDB单步),监测哪个err = context_init[i].init(kctx);:
# 加入的断点调试
printk("[gpu/%s] kctx->process_mm->rss_stat[0]:%p\n", __func__, &kctx->process_mm->rss_stat[0]);发现在i=1时,&kctx->process_mm->rss_stat[0]数值**不为0**。 **注意**:如果没有正常代码作为对比,则需要审查这部分的所有代码。 对比我们调试的代码,在执行完kbase_context_common_init还是0那么需要深入挖掘里面的问题。 我们看到如下: 
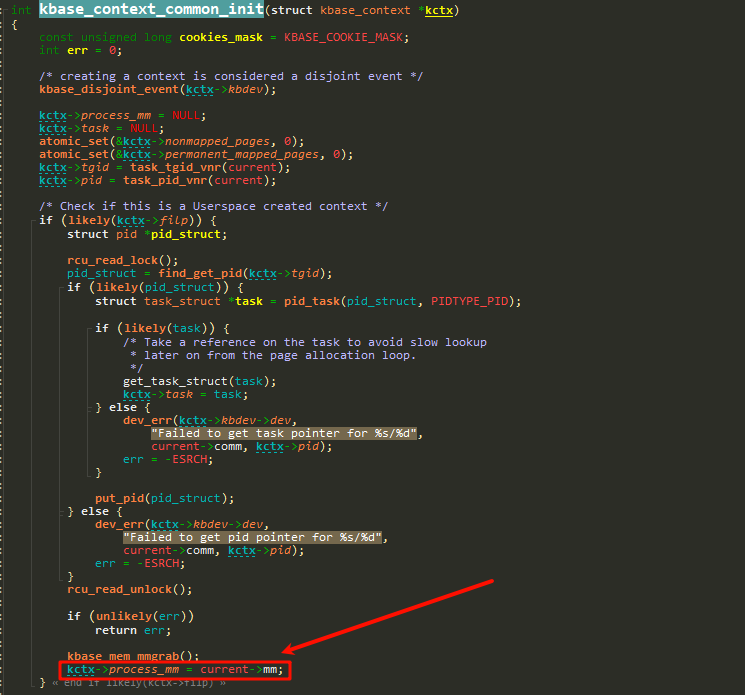 这里可以清晰看到
这里可以清晰看到kctx->process_mm实际上是来自current。那么这里的问题不再是GPU驱动问题了。 
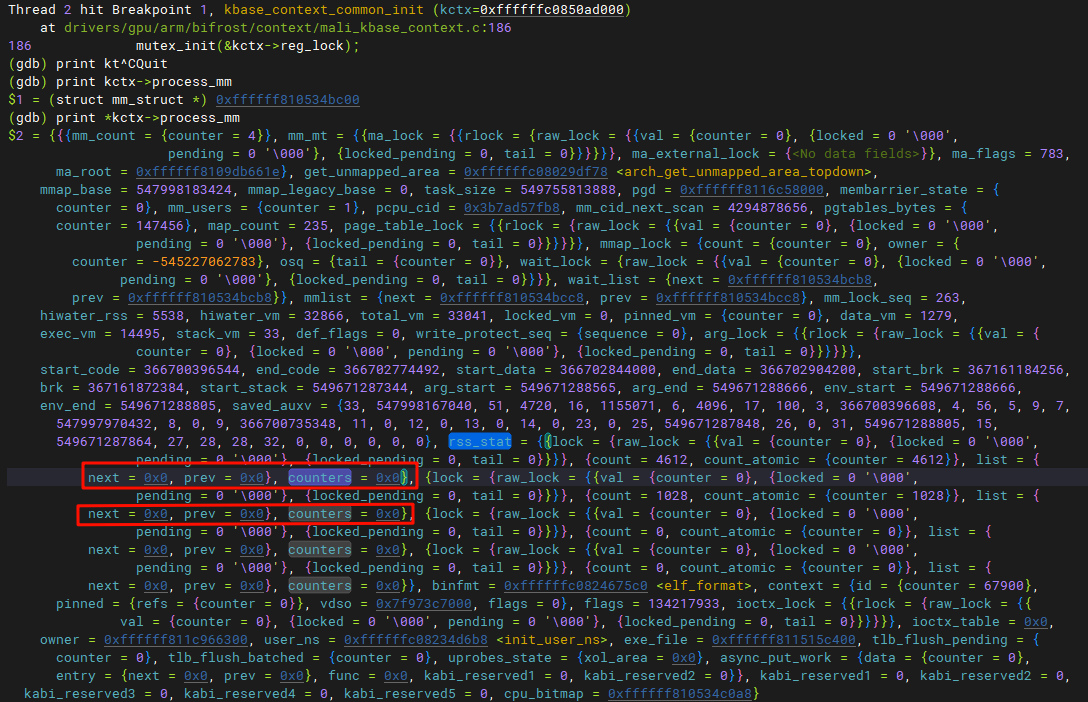 正常的代码,这里是有数据的(对比法)。
正常的代码,这里是有数据的(对比法)。 current是一个宏,表示当前的内核线程,我们使用info threads,发现当前的内核线程停在了Xorg。 

深入挖掘进程与内核线程的问题
上面寻找问题可以看到,问题不再是
GPU驱动问题,我们需要深入到进程的创建过程中,我们知道,在内核中是没有进程这个概念的,只有任务以及PID。
现在,我们需要找到创建Xorg进程的内核代码,并且跟踪current->mm->rss_stat[0])->counters的数值变化。 这里我们需要知道一些基本的知识,Xorg是X Window系统的服务器部分,我们切换到旧核心(正常进入系统),然后使用命令查看它的相关进程:
pstree
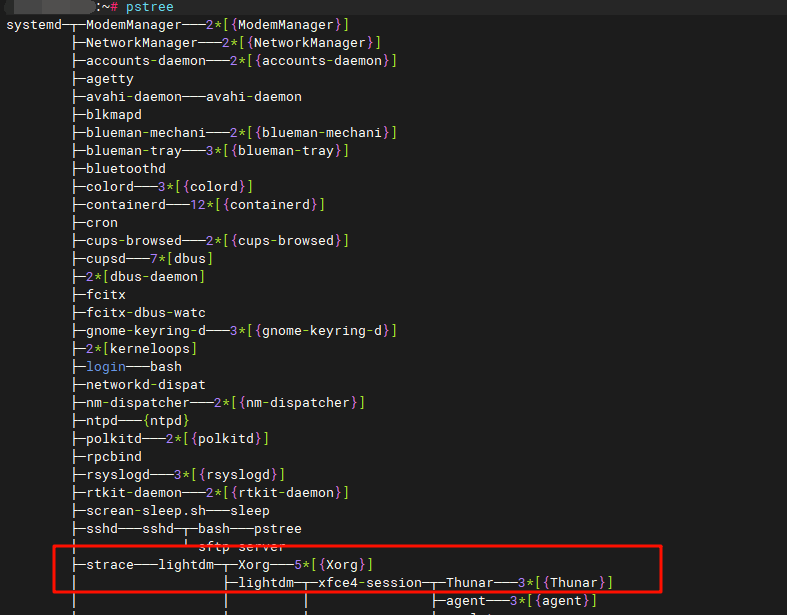 这里的
这里的strace是我加入了调试,实际上systemd->lightdm->Xorg这才是真正的调用树。那么我们查看下lightdm服务: 
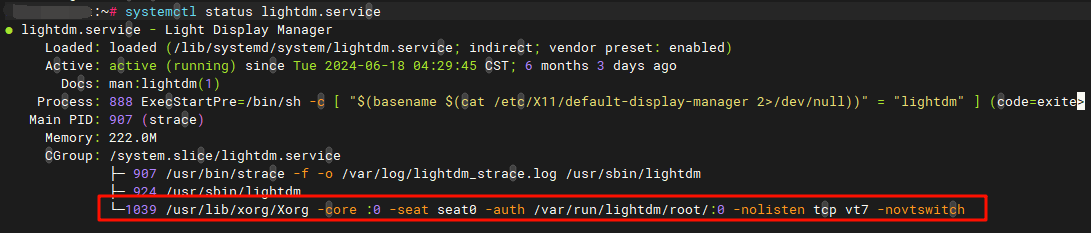 我们希望找到具体的syscall调用
我们希望找到具体的syscall调用Xorg,我们可以修改服务: 
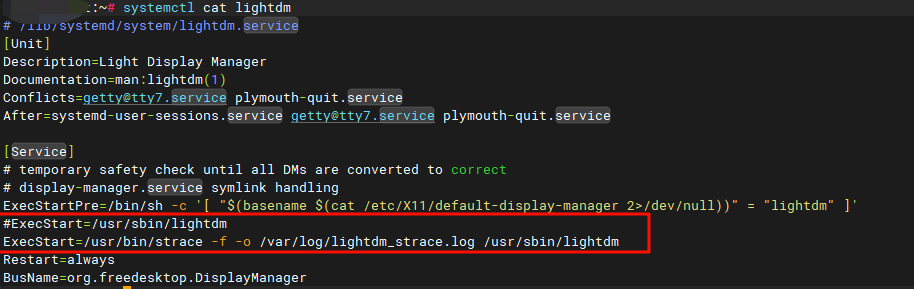
ExecStart=/usr/bin/strace -f -o /var/log/lightdm_strace.log /usr/sbin/lightdm重新启动后,我们将lightdm_strace.log导入到klog中查看: 
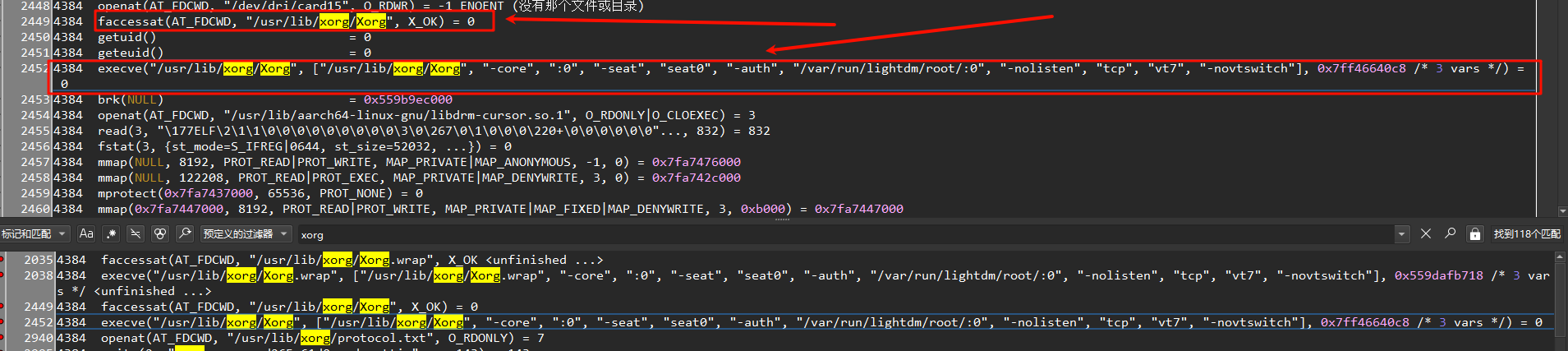 这里使用
这里使用faccessat先验证"/usr/lib/xorg/Xorg"是否可以执行,然后再执行Xorg命令。 注意:在这里,我们需要先知道一个知识点,用户层执行一个命令,通常是先fork自己,形成一个子进程,然后在子进程中执行execve,读取程序的elf文件。 所以,在这里,我们先需要找到lightdm进程的创建,接着我们需要找到Xorg。在花费一些时间后,我们找到了lightdm的fork过程: 在我们服务(命令行)执行了/usr/lib/xorg/Xorg,首先内核中会进入fork:
# kernel\fork.c
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
pid_t kernel_clone(struct kernel_clone_args *args)
{
......
p = copy_process(NULL, trace, NUMA_NO_NODE, args); //复制一个进程
add_latent_entropy();
......
}我们需要找的是关键的复制struct task_struct位置。 同时我们也找到了Xorg的执行位置:
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}我们在do_execve加入调试点:
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
//printk("[Ktask/%s] kernel_filename:%s\n", __func__, filename->name);
if( !strcmp( filename->name, "/usr/lib/xorg/Xorg"))
{
printk("[Ktask/%s] current->mm->rss_stat->count[0]:%p\n", __func__, ((struct percpu_counter *)¤t->mm->rss_stat[0])->counters);
printk("[Ktask/%s] running /usr/lib/xorg/Xorg ,PID(%d)\n", __func__, task_pid_vnr(current));
}
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}同时在fork过程也加入调试点,最终确定了在fork过程错误点(具体就是通过旧版本/正常本部同时对比):
copy_process
dup_task_struct
arch_dup_task_struct上面并没有问题,问题是在copy_process复制完父进程结构体后,进行的copy_mm位置:
copy_mm
dup_mm
mm_init里面的部分代码被修改,去除了percpu_counter_init_many代码(某个同事修改了),导致mm被清空后,也不会赋值一个有效值。 最终加入该条代码,GPU可正常启动。
其他
上面的分析内容大家不一定会经常遇到。但是,可以借鉴上面的分析过程,在这个前提是需要完备的
OS系统知识,编译工具链使用,精通C语言,KGDB/GDB,ARM架构,系统调用,同时对图像系统(用户层)需要有大概的了解。 所以我们在分析一个复杂问题时,这些并不突出的技能,会帮助我们一步步解决该问题。
贡献者
 Px
Px